This “new” game has a special place in my heart. It’s a re-imagining of a game I played all the time in high school back in the early 2000s. Late nights spent with friends pre-cable internet. Using our AOL connections and firing up Acrophobia. Making inside jokes and coming up with clever acronyms to make each other laugh (and hopefully score points too!). I actually wrote a version of this back in 2017 as part of my prototypes that came before Gametje. This one is luckily far more polished visually and with proper gameplay mechanics. Meet AcroByte:
Here’s the basic gameplay loop. Players are given a random acronym and a category and must write a phrase that matches. Then players vote on their favorites and points are awarded. It starts with a 3 letter acronym, then 4, 5, 6, 7 and then cycles back to 3. A “faceoff” round is activated once the top player hits a set score. The top 2 players then faceoff in 3 speed rounds to determine the winner.
To ensure I generate appropriate acronyms for each language, I found the top 50,000 words for each. I whipped up a script with Claude’s help to analyze these files and output their first letter frequency. The script was far better than the one I wrote in 2017. I used the data from here.
First letter analysis
While analyzing the data for each language, I was curious to compare their most frequent first letters to see if I could discern any patterns. Here are the top 10 first letters for each language. I’ve separated them into Germanic, Romantic, and Slavic for comparison sake.
The Germanic Languages
| English | Dutch | German | Danish | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
The Romance Languages
| Spanish | French | Portuguese | Romanian | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
The Slavic Languages
| Polish | Slovak | ||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
Here's a letter breakdown (some letters are missing that were not present in any language's top 10):
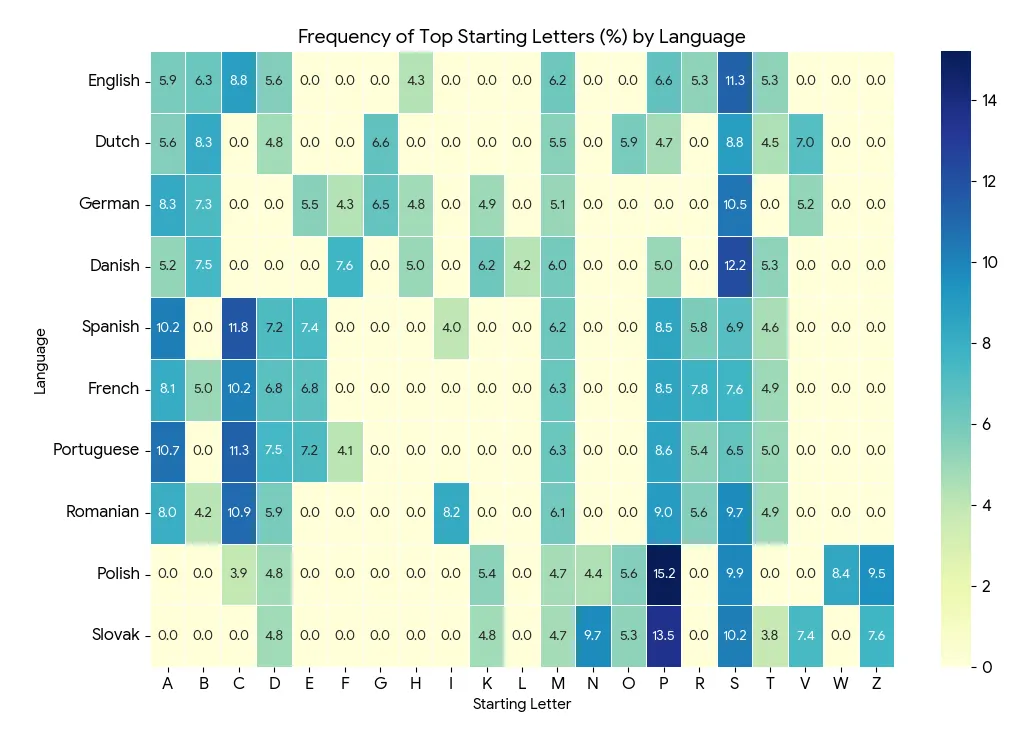
Observations
- “S” is present in each languages top 10. It is the most common starting letter across the languages Gametje supports.
- “M” is 2nd place as it also appears in the top 10 for every language.
- Vowels vs. Consonants: The Romance languages (“C” group) are much more likely to start words with vowels (A, E, I) than the other two groups.
- As expected, English bridges the gap between Germanic and Romantic languages with S and C as their top 2.
| Family | Top Letters | Rare in other language groups |
|---|---|---|
| Germanic | S, B | H |
| Romance | C, P, A, D, | C (as #1), High A |
| Slavic | P, S, Z, N | Z, N, W (Polish) |
Normalizing “special” characters
As a part of this research to support multiple languages in the platform, I actually found a bug in Canvas Clash. Specifically with the word “elephant” in French which translates to ‘Éléphante’. You’ll notice it has 2 ‘é’ characters which causes an issue if you are trying to guess using a standard keyboard. Canvas Clash currently allows for 1 typo based on the Damerau–Levenshtein distance but this would be 2 if you wrote ’elephante’. I wrote about this algorithm a bit in the Sync Think blog earlier this year.
I knew for acronyms, I’d need to solve this problem in a better way and “normalize” these special characters. I found that Java has decent support for Normalization/decomposition of letters using Normalizer.Form.NFD. This helps separate base chars from diacritics. There are also some unique characters in Danish and other languages that could also be normalized. For instance, the decomposition of æ->ae->a from Danish. This of course applies to both the acronym itself and the submitted input. I’d rather the game was too flexible than too strict as ultimately it is the other players making the judgement call.
For the curious, here’s the normalizing code that AcroByte is using:
import java.text.Normalizer;
import java.util.regex.Pattern;
public class WordNormalizerUtil {
public static String normalizeAccentsAndSpecialChars(String input) {
if (input == null) {
return null;
}
String result = input
// Polish
.replace("Ł", "L").replace("ł", "l")
// Croatian, Serbian, Vietnamese
.replace("Đ", "D").replace("đ", "d")
// Scandinavian
.replace("Ø", "O").replace("ø", "o")
.replace("Å", "A").replace("å", "a")
// Icelandic
.replace("Þ", "TH").replace("þ", "th")
.replace("Ð", "D").replace("ð", "d")
// German
.replace("ß", "ss")
// Ligatures
.replace("Æ", "AE").replace("æ", "ae")
.replace("Œ", "OE").replace("œ", "oe")
// Turkish (special I handling)
.replace("İ", "I").replace("ı", "i")
// Celtic
.replace("Ŵ", "W").replace("ŵ", "w")
.replace("Ŷ", "Y").replace("ŷ", "y")
// Icelandic/Faroese O with horn
.replace("Ơ", "O").replace("ơ", "o")
.replace("Ư", "U").replace("ư", "u");
// Normalize to NFD (decomposed form) - separates base chars from diacritics
String normalized = Normalizer.normalize(result, Normalizer.Form.NFD);
// Remove all diacritical marks (combining characters)
Pattern pattern = Pattern.compile("\\p{InCombiningDiacriticalMarks}+");
return pattern.matcher(normalized).replaceAll("").substring(0, 1);
}
}
New language detected - Portuguese support
Regular readers of the blog will have noticed a new language in the mix. Gametje is now playable in Portuguese, rounding it out with 10 languages supported! I’ve also streamlined the tools necessary to add a new language to the platform. If you have a request for a new language, please let me know. I created some internal tools to help “catch up” translation using AI for i18n keys. This will allow me to write new text in English, run the script and have it automatically translated and placed in the correct order in my json translation files. I sadly used to do some of this work manually.
Game Options
All games have their own set of options. Most are common across games such as number of rounds, tutorial enabled/disabled or music on/off. There are however a couple games with extra options:
- Sync Think has “close matches” enabled which sends all the non-exact matches over to ChatGPT to determine if the submissions were “referring” to the same thing. e.g. Developer <-> Software Engineer.
- AcroByte has some more concrete options that affect the game play

I wanted to allow users to play it their own way. In particular, being able to set the “faceoff” score threshold and the acronym length felt important for this game. Some people just don’t want to have to come up with an answer for a 7 letter acronym.
Thanks for reading. Have some ideas to make AcroByte better? Use my contact form.