You heard it here folks. I’m introducing a spinoff site for daily games. Think of it a bit like Wordle but directly tied to the games on my main site. The first daily game I am creating will be a new concept called Noun Sense.
It’s a game about adjective and noun association. The basic gameplay loop is simple: you are given 10 adjectives each day, and you have to guess the most frequently used noun that follows each adjective. The more frequent the usage in common English, the higher the score. A maximum of 100 points are awarded with total max score of 1000 each day. I crunched some massive text files combining sources from movies, magazines, news articles, Wikipedia and even transcripts from Ted Talks. The data set should be pretty fair for the average native English speaker.
Sound interesting? It’s already live here: daily.gametje.com. Give it a shot and then come back for the implementation details below.
The idea
While I was at PGConnects London, I met several people with good game ideas for gametje.com. One idea came from a fellow developer named Demid who mentioned a game he had played quite a few years ago that stuck with him. It was a game called Word after Word. Here’s a short description from the itch.io page:
Word After Word is a fast-paced local multiplayer word game that uses a massive natural language dataset to reward players for thinking naturally about common word usage and context.
I watched the gameplay video and was immediately hooked and wanted to create my own version. The main issue was getting a good dataset and writing a script to process it.
Data crunching
In order to generate good adjective/noun pairs, I needed a data set to start with. I first tried using a dataset of public domain books from Project Gutenberg which is a collection of old books where the copyright has already expired. There were tons of books to choose from but they contained quite archaic language which made it difficult to guess. I wanted it to be more accessible to common English so I decided to use news and magazine articles, movie subtitles, and other more frequent media. This produced a much more natural result.
Writing the script
I’m no stranger to natural language processing (NLP) but it had been a little while since I used it. Python is typically the programming language of choice for NLP. There are tons of libraries that help and many examples on the internet. I decided to use Google’s Gemini to help me write a python script to crunch all the data. I know python a little bit from earlier in my career but I knew these LLMs can really crank out one-off scripts quickly. All it takes is a few sentences describing the concept and it was able to quickly generate a script with the best python libraries to help.

Fine tuning
It took a fair amount of back and forth with Gemini to get the final script correct. I started first with the NLTK library to parse the large data sets and grab the adjective/noun pairings. After testing a few iterations with different data sets, I found this library to be insufficient as it was only guessing about adjectives and nouns. You ended up with proper nouns and nouns describing nouns (like “Sun Dial”) muddying the waters of the real answers. NLTK uses a statistical model that tries to guess about adjectives and nouns rather than “knowing” the parts of speech of the words. It might work with more tuning but I knew there was a better library.
Enter spaCy. spaCy is the modern industry standard. It doesn’t guess based on statistics like NLTK. It uses word vectors (multi-dimensional representations of word meanings) to determine the parts of speech. After processing the dataset with this library, it immediately produced much more natural results. I found myself scoring much higher and the answers “made sense” when spot checking them. This library is quite a bit slower and thorough thatn NLTK so it took a lot longer to process the files. I tweaked the script to add a few necessary improvements. I added a completion percentage to track remaining time, and built in checkpoints so I could pause the script without losing any data. I also added caching so it can pick up where it left off more easily and also generate the final pairings without having to process again.
The original dataset produced 176,000 unique adjective/noun pairs. I needed to tweak the minimum nouns associated to an adjective and the minimum frequency to prune the data set downward. This ensured a higher quality data set and also gave me less data to store in the database. I think in total it took around ~16 hours of processing on my Macbook M1 to process the billions of words/sentences to generate the final data set. That doesn’t include the countless hours of fine tuning and trying different data sets. It’s amazing how fast even these consumer laptops can process text.
Scoring algorithm:
In order to make the game more fun, I wanted to scale the scoring based on the Magnitude (Logarithm) of the frequency. This will reward being “in the ballpark” of a popular answer without punishing you for not picking the statistically dominant outlier. If a word is 10x more likely than everything else, you’ll still get a decent amount of points for the second or third most frequent answers.
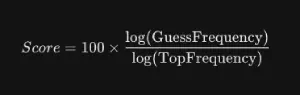
Look and feel
I already have an established codebase for the main gametje.com website. It is written in Typescript/React but it has felt a bit slow to load at times. I’ve done quite a lot of work around code splitting and lazy-loading to allow it load faster but I was unhappy with the results. For this daily game concept, I decided to experiment with SvelteKit instead of React. The learning curve was quite small coming from React and the results and iteration speed were really impressive. I also incorporated Tailwind CSS for help with styling. I was really impressed with how quickly I could go from zero to working concept with these frameworks in place. I was able to reuse a lot of code around the APIs and websockets from the main site in this new code repository and everything loaded much snappier. I am considering moving the whole main site over to this framework but that is for another day.
Check out a screenshot of a game played today:

The game has been optimized to be played on a mobile phone. It is also created as a Progressive Web App (PWA) so you can actually install it like a regular app on your phone. Here are some instructions for Android and iPhone to install the PWA. It will show up on your desktop looking a bit like this:
Leaderboard
What’s a daily game without a little bit of friendly competition? I knew if I wanted the game would catch on, there needed to be an easy way to compete and share with your friends. I’ve seen first hand the discussions of the daily Wordle and how many tries it took you to complete. Noun Sense has a more tangible comparison as you get up to 100 points per adjective for the top answer (Max daily score is 1000). I decided to create a Leaderboard page where you could see your overall placement and added a sharable image after you complete the day. Here’s a sample shared image from today:


Friends
My initial leaderboard just had everyone who played on a given day. When there are only 5-10 people playing it, it was feasible to just include everyone but the idea is to have many people playing so this did not scale well. I also did not want everyone’s personal data on display without their consent. I decided to add a friend system which would allow you send and receive friend requests. Using those associations I could easily craft everyone’s own personal leaderboard.
Planned Improvements
- Add a streak system - this will encourage people to come and play each day to maintain their streak.
- Add the multiplayer version - I think the initial version will be cooperative, sort of family feud style game. Where you are given a certain amount of time and you must score enough points to pass the round. You’ll be able to submit as quickly as you can and score points for your team. I could also make it a team vs team mode or just an individual free-for-all. There are a lot of ways to go with it.
- Align the daily site and the main site - Refactor the main site to use SvelteKit everywhere for better speed and SEO capabilities.
If you made it this far, thanks for reading! Here’s a happy sushi for you.
